일반적인 DNN (Deep Neural Network)은 기본적으로 1차원 형태의 데이터를 사용한다. 따라서 이미지가 입력될 경우, 이것을 flatten 시켜서 한줄의 데이터로 만들게 된다. 이 과정에서 이미지의 공간적 정보가 손실되어, 특징 추출과 학습이 비효율적이고 정확도의 한계가 발생한다는 문제가 있었다. 그래서 CNN(Convolutional Neural Network)을 통해 이미지를 raw input으로 받음으로써, 공간적/지역적 정보를 그대로 유지한채 특성들의 계층을 빌드업하게 된다.
Convolutional Layer

기본적으로 Convolutional Layer에는 input 값인 이미지와 필터(=합성곱 커널 : convolution kernel)가 있다.

위의 그림처럼, 필터(=커널:kernel)가 이미지의 위에서부터 차례대로 내려오면서 Dot products를 진행한다. 다시 말해 32 x 32 x 3의 크기의 이미지에 5 x 5 x 3의 필터로 차례대로 훑고 내려오면서 5 x 5 x 3 (75번)의 Dot product 연산을 한다. 또한 각각의 Dot product 결과로 하나의 숫자를 return 한다. 즉, 필터가 위치해있는 하나의 location 당 하나의 숫자로 표현되는 것이다.
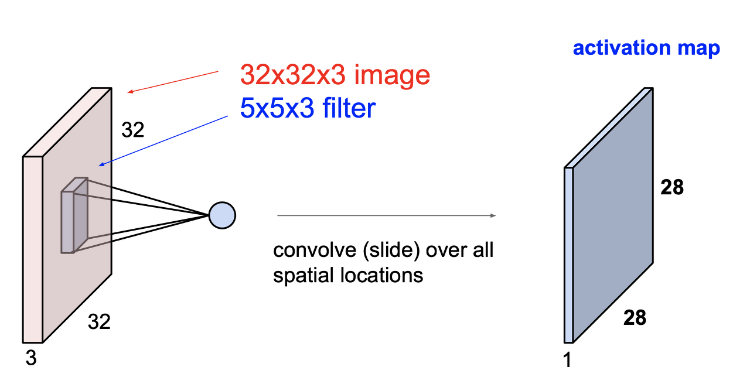
이때 convolution layer(합성곱 층)의 뉴런은 입력 이미지의 모든 픽셀에 연결되는 것이 아니라, convolution layer 뉴런의 수용장 안에 있는 픽셀에만 연결된다는 특징이 있다. CNN에서 필터의 크기 (위의 경우에는 5 x 5 x 3)는 파라미터의 수를 의미하며 하나의 필터는 하나의 activation map(= 특성맵 : feature map)을 생성한다.
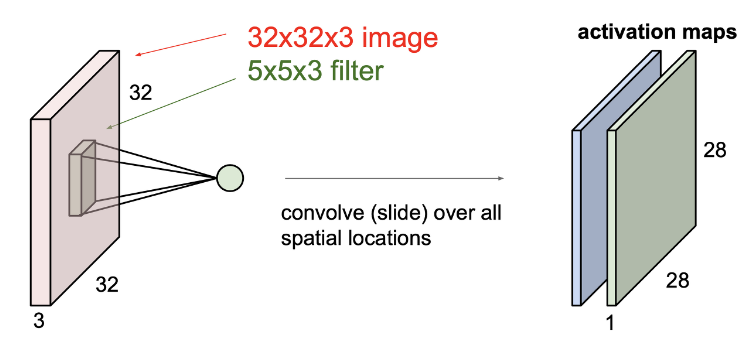
따라서 위와 같이 위쪽의 input 이미지에 2개의 필터를 적용했다면 오른쪽 그림과 같이 2개의 activation maps가 생성된다.
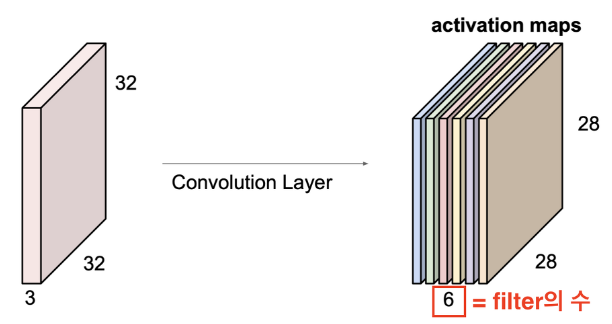
input으로 들어온 이미지를 activation의 관점에서 representation을 하면 오른쪽과 같이 새로운 형태의 이미지로 변환되는 것이다. 이때 새로 생성된 activation maps의 depth는 적용한 필터의 수와 동일하다. 이렇게 생성된 activation map을 다음 layer의 input값으로 전달된다.
Stride

위 그림과 같이 input으로 7 x 7 크기의 이미지가 들어올 때, 여기에 3 x 3 필터를 적용해보자.

stride는 한 필터와 다음 필터 사이의 간격과 같다. 예를 들어 위 그림과 같이 stride를 1로 설정했다는 것은 필터와 다음 필터 간격이 1이라는 의미가 되고 1칸씩 가로, 세로 방향으로 이동하면서 이미지에 필터가 적용된다. 다시 말해, 7 x 7의 크기를 가진 이미지에 3 x 3의 크기를 가진 필터릴 stride 1로 적용하면 가로, 세로 각각 총 5칸씩을 이동할 수 있으므로 output으로 5 x 5의 크기를 가진 activation map이 생성되는 것이다.
Pooling Layer
CNN에서 padding을 이용해서 사이즈를 보존해주되, 동시에 사이즈를 점점 줄여나가는 것이 중요하다. 따라서 pooling layer에서는 down sampling을 담당한다.

위의 그림과 같이 pooling layer에서 down sampling을 진행한 결과 사이즈가 절반으로 줄어들었음을 알 수 있다. 이러한 작업은 각 activation map에 독립적으로 적용되며 이 때 depth는 그대로 유지된다.
'Deep Learning' 카테고리의 다른 글
| [Keras] VGG-net (0) | 2022.09.01 |
|---|---|
| RNN(Recurrent Neural Network) 순환 신경망 (0) | 2022.08.19 |
| [Deep Learning] 앙상블 학습(Ensemble Learning) (0) | 2021.07.29 |
| [Deep Learning] 배치 정규화(Batch Normalization) [작성중] (0) | 2021.07.29 |
| [Deep Learning] 활성 함수(activation function) 정리 (0) | 2021.07.28 |



댓글